
The πᵉ Manifesto
Why Growth Rate Beats Size and Why the Edge Forces New Theory


We chose πᵉ because it marks a boundary.
It is a number we can compute to arbitrary precision, yet cannot classify with existing mathematics. After more than a century of effort, we still do not know whether πᵉ is rational, algebraic, or transcendental. Not because the number is complicated — but because every known tool is structurally incapable of answering the question.
That gap matters. It tells us where current theory ends. And it tells us where new theory must begin.
Fact Check
Before anything else, the numbers:
eᵖ ≈ 23.1406926
πᵉ ≈ 22.4591577
So: eᵖ > πᵉ. No controversy. No approximation error. This is a provable inequality.
Why intuition gets this wrong. Most people compare bases — π ≈ 3.14 is bigger than e ≈ 2.72 — and assume the bigger base should produce the bigger result. That reasoning works for linear comparisons. It fails for exponential ones, because exponents dominate growth behavior, not bases.
The correct comparison. Take natural logarithms of both sides. The question eᵖ > πᵉ becomes:
π vs e·ln(π)
Evaluate:
π ≈ 3.1416
e·ln(π) ≈ 2.718 × 1.1447 ≈ 3.113
So π > e·ln(π). That inequality — not the raw size of the bases — is the core reason eᵖ wins.
Why this is structural, not accidental. The comparison reduces to a deeper fact. The function
f(x) = ln(x) / x
has a unique global maximum at x = e. Its derivative is (1 − ln(x))/x², which is zero at x = e and negative for all x > e. So f peaks at e and then strictly decreases.
This means:
e is the optimal base for exponential growth relative to its size. No other number converts magnitude into growth as efficiently.
Any number larger than e — including π — is less efficient per unit of magnitude as a base.
Since π > e, we have f(π) < f(e), which gives:
ln(π)/π < ln(e)/e = 1/e
Multiply both sides by eπ:
πᵉ < eᵖ
One function. One critical point. One inequality. The proof is complete.
The right mental model:
π is larger — but inefficient as a base. It wastes magnitude through suboptimal growth scaling.
e is smaller — but maximally efficient at converting exponent into growth. Every unit of exponent produces maximum return.
The exponent amplifies structure, not magnitude.
That is why e as a base beats π as a base, even when π is the exponent.
One-sentence takeaway: This inequality is not a numerical coincidence. It follows from the fact that e uniquely maximizes logarithmic growth efficiency, so exponentiation amplifies structure, not raw size.
That is the mathematical foundation of everything that follows.
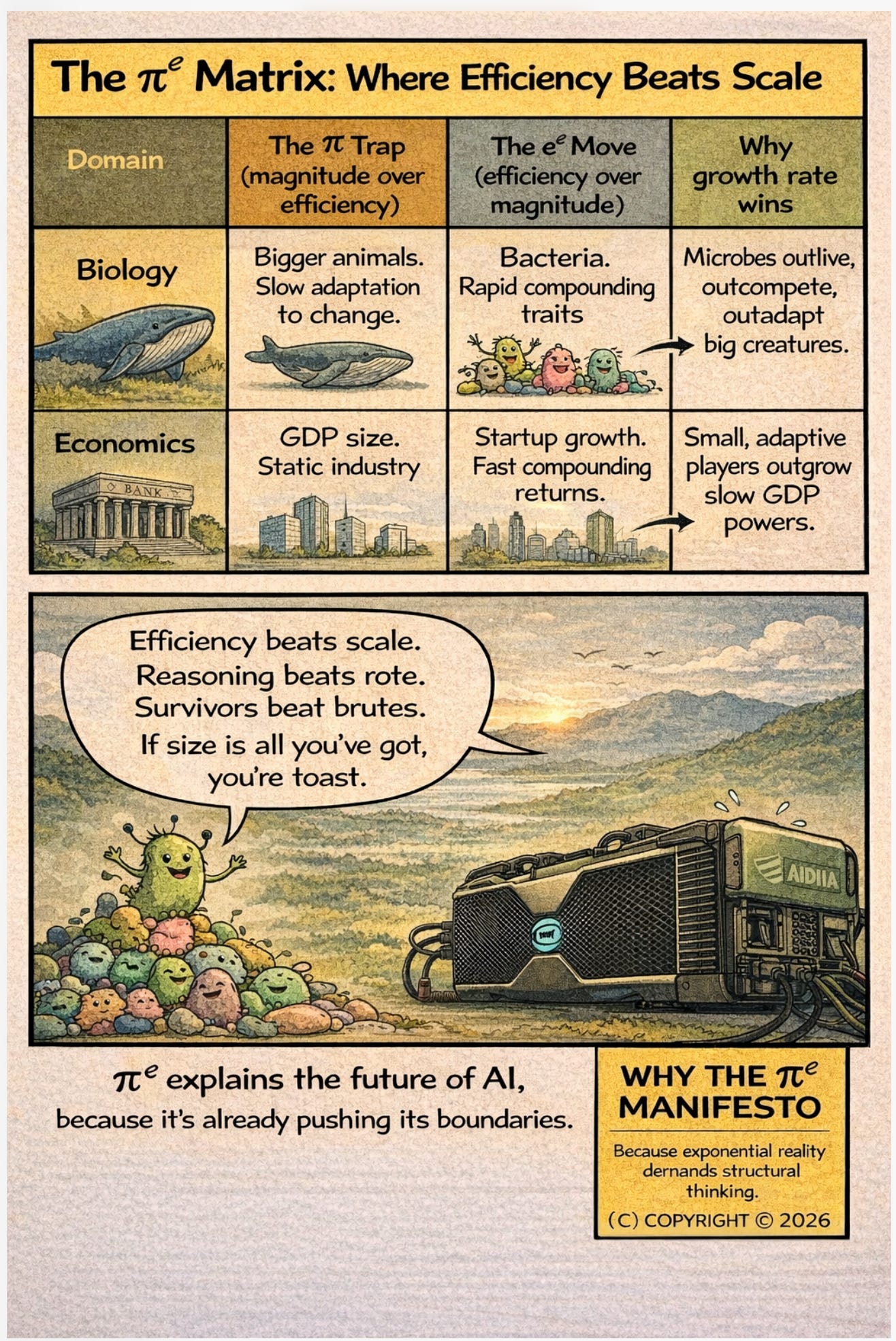
I. Growth Rate Beats Size
There is a precise mathematical fact that most intuition gets wrong:
eᵖ > πᵉ 23.141 > 22.459
Even though π is larger than e, the expression with e as the base wins. The reason is not numerical accident. It is structural.
The proof. Take logarithms of both sides. The question eᵖ > πᵉ becomes: is π > e·ln(π)? Equivalently: is 1/e > ln(π)/π? Now consider the function f(x) = ln(x)/x. Its derivative is (1 − ln(x))/x², which is zero at x = e and negative for all x > e. So f peaks at e and then decreases. Since π > e, we have f(π) < f(e), which gives us ln(π)/π < ln(e)/e = 1/e. Therefore eᵖ > πᵉ.
One function. One critical point. One inequality. Done.
The deeper content is not the inequality itself but what it reveals. The function f(x) = ln(x)/x measures how efficiently a number converts magnitude into growth. It has a unique global maximum at x = e. No other number compounds more efficiently. Every larger base wastes some of its magnitude through suboptimal scaling. Every smaller base lacks the raw material to compound.
e is not just a number. It is the point where growth efficiency is maximized. And when you put an efficient base in competition with a larger but less efficient base, efficiency wins — provided it has enough structure to compound against.
That “enough structure” is π. Full geometric complexity. The complete description of circular, rotational, and periodic physical systems. When optimal efficiency (e) compounds over full physical structure (π), the result is 23.141 — larger than what raw magnitude (π) achieves when scaled by natural growth (e) alone.
This is not metaphor. It is a theorem.
Optimal growth rate outperforms raw size when compounded over sufficient structure.
That principle appears everywhere: in algorithmic complexity, where O(n log n) beats O(n²) not at small n but inevitably; in biology, where metabolic efficiency determines which organisms survive energy constraints, not body mass; in finance, where compound interest at a lower rate on a longer horizon beats a higher rate on a shorter one; in thermodynamics, where entropy production efficiency determines equilibrium states, not energy magnitude.
And now, in intelligence.
II. The Mistake of Scale Absolutism
Modern AI has been built on a single dominant strategy: scale.
More parameters. More data. More compute. The scaling laws published by OpenAI in 2020 and confirmed by subsequent work showed smooth, predictable improvement as models grew. This created a reasonable inference: if bigger is reliably better, then biggest wins.
That inference is correct within its regime. And its regime is ending.
Scale assumes you can average away uncertainty. With enough data, noise cancels. With enough parameters, the model finds the pattern. With enough compute, gradient descent converges. These are not wrong — they are conditional. They hold when data is abundant, independent, and identically distributed. When errors are recoverable. When latency is free. When you can step outside the system to observe it.
Those conditions describe a data center. They do not describe the physical world.
The moment intelligence leaves the server rack and enters a vehicle, a factory floor, a surgical suite, a battlefield, a power grid, or a body — every one of those assumptions breaks simultaneously:
Decisions become irreversible. A robotic arm that moves has moved. A vehicle that brakes has committed to braking. You cannot roll back a physical action and try again. Every decision is final on the timescale that matters.
Latency becomes binding. A 200-millisecond round trip to a cloud server is not “fast enough” when a human steps into a crosswalk and your vehicle is traveling at 60 km/h. At that speed, 200 milliseconds is 3.3 meters of uncontrolled motion. Physics does not wait for your API call.
Energy becomes finite. An edge device runs on watts, not megawatts. A sensor node in a remote location runs on milliwatts. You cannot solve every problem by throwing more FLOPS at it when your entire power budget is smaller than a laptop charger.
Data becomes local and non-IID. The data arriving at a sensor in a steel mill is not a random sample from a well-behaved distribution. It is autocorrelated, non-stationary, locally structured, and sparse. The central limit theorem does not rescue you. Your model must work with what it sees, not with what a training set promised.
Failure costs become asymmetric. A wrong recommendation on a social media feed costs an advertiser a fraction of a cent. A wrong classification on a manufacturing line costs a defective product. A wrong decision on a medical device costs a life. The cost function is not smooth, differentiable, and bounded. It is discontinuous, catastrophic, and one-sided.
In this regime, expectation-based optimization is insufficient. Averaging is no longer safety. Convergence is no longer correctness. The law of large numbers does not apply when n = 1 and the decision is irreversible.
Growth rate — not size — decides outcomes.
III. Edge Intelligence Is a Different Regime
Edge systems are not “smaller cloud systems.” This is the most common and most dangerous misconception in the industry.
A smaller cloud system is a cloud system with fewer resources. It operates on the same principles, makes the same assumptions, and fails in the same ways — just sooner. Shrinking a transformer and deploying it to an edge device does not make it an edge-native system. It makes it a cloud system that runs out of memory faster.
Edge-native systems are built on different foundations:
Correctness is defined by admissibility, not optimality. A cloud system seeks the best answer. An edge system seeks any answer within the set of safe, physically valid, constraint-respecting responses. The optimal answer that arrives 50 milliseconds late is worse than the admissible answer that arrives in 5. Admissibility is a set-membership problem. Optimality is a search problem. They are structurally different.
Structure matters more than statistics. At the edge, you often know the physics of your problem. You know the equations of motion, the material properties, the sensor geometry, the kinematic constraints. That knowledge is not a “prior” to be updated by data — it is a hard constraint that no amount of data should violate. A neural network that predicts a steel beam will bend upward under load has not found a surprising pattern. It has made a physically impossible error. Structure must be embedded, not learned.
Local validity matters more than global convergence. A cloud model can afford to be wrong locally if it converges to the right answer globally over millions of samples. An edge system cannot. Every local decision must be valid on its own terms, because there may not be a “global” to converge to. The bridge you are monitoring does not care about your model’s performance averaged across all bridges.
Physics is not a dataset — it is a constraint. The laws of thermodynamics, conservation of energy, Newton’s laws, Maxwell’s equations — these are not patterns to be extracted from data. They are invariants that hold regardless of data. An edge AI system that violates conservation of energy has not “generalized creatively.” It has failed. Physics is the boundary condition within which all valid inference must occur.
An edge system that makes forty correct-enough decisions in the time a cloud system makes one perfect decision wins. Not eventually. Immediately. Not statistically. Every single time it matters.
This is the same inequality, made physical. Efficiency (e) compounded over structure (π) outperforms magnitude (π) scaled by growth (e).
IV. Compute Without Full Theory Is Not a Bug
πᵉ exposes an uncomfortable truth about the relationship between capability and understanding:
You can compute perfectly without fully understanding.
We can calculate πᵉ to billions of digits. We can use it in equations, compare it to other constants, embed it in algorithms. It is as operationally available as any number in mathematics. And yet we cannot answer the most elementary question about its nature: what kind of number is it?
This is not a failure of computation. It is a demonstration that computation and classification are independent capabilities. You do not need to classify a number to use it. You do not need to understand a system to operate it.
This pattern has a specific origin.
The Manhattan Project was the first industrial-scale demonstration that you can compute far ahead of theory and make it work — if you bound what you don’t know.
In 1943, the physics of nuclear fission was incomplete. Cross-sections for key reactions were uncertain. The behavior of plutonium under implosion was not analytically solvable. The theory of neutron transport in complex geometries did not exist in closed form. None of this was settled science.
They built the bomb anyway.
Not recklessly. They invented methods to work responsibly in the absence of complete theory. Monte Carlo simulation — now foundational to all of computational science — was created at Los Alamos specifically because analytical solutions did not exist for neutron diffusion. They could not solve the equations, so they simulated them stochastically, bounded the uncertainty, and computed their way to answers that theory could not yet provide. Feynman, von Neumann, Ulam, and Metropolis built the first computational infrastructure for reasoning under theoretical incompleteness.
They validated empirically. The Trinity test was not a demonstration — it was a measurement. The theoretical predictions for yield ranged from near-zero to 20 kilotons. The actual yield was 21 kilotons. Theory was not precise enough to predict the outcome. Computation and empirical validation carried the project where theory could not.
They enforced invariants. Conservation of energy, conservation of momentum, known nuclear binding energies — these held regardless of whether the detailed transport theory was complete. The things they knew for certain became hard constraints. The things they did not know were bounded, simulated, and tested.
They designed margins of safety. Criticality calculations included explicit safety factors because the underlying physics had quantified uncertainties. The margins were not guesses — they were engineering responses to known unknowns.
Capability preceded explanation. The bomb worked in July 1945. The theoretical understanding of why it worked as well as it did — the detailed reconciliation of predicted versus observed yield, the refined cross-section measurements, the mature theory of implosion dynamics — took years to decades to fully develop.
The same pattern repeats throughout history. Steam engines worked for over a century before Carnot, Clausius, and Kelvin developed thermodynamics. Airplanes flew before boundary layer theory existed — the Wright brothers built a wind tunnel and tested empirically because the equations were not solvable. Evolution operated for 3.8 billion years before genetics existed. Vaccination worked before immunology.
But the Manhattan Project is the cleanest case because it was deliberate. They knew theory was incomplete. They chose to compute anyway. They invented the methods to do it responsibly. And those methods — Monte Carlo simulation, computational bounding, empirical validation against invariants, quantified margins of safety — became the foundation of modern computational science.
That is the lineage we are claiming.
Not “edge engineers already do this.” Most don’t — not rigorously, not with the Manhattan Project’s discipline around bounding what they don’t know. The industry mostly deploys models and hopes they work. That is not the same thing.
What we are building is the deliberate practice of operating ahead of theory: computing what we cannot yet classify, bounding what we cannot yet prove, enforcing what we know to be invariant, and maintaining quantified margins against what we do not know. Not recklessly. Not by hoping. By method.
This is how new theory is born. The theory follows the practice, because the practice generates the problems that theory must solve. The Manhattan Project generated problems that drove fifty years of nuclear physics, computational science, and probability theory. Edge AI physics will generate problems that drive the next generation of intelligence theory.
We intend to be the practice that forces the theory.
V. Why Existing Theory Breaks
Every major theorem that classifies irrational and transcendental numbers relies on one structural requirement: an algebraic anchor.
Hermite proved e is transcendental in 1873. The proof works because e can be characterized through its relationship to rational numbers via the exponential series — the algebraic structure of the rationals provides the anchor.
Lindemann proved π is transcendental in 1882, extending Hermite’s method. The key step uses the fact that eⁱᵖ = −1 (Euler’s identity), which connects π to the algebraic number −1 through the exponential function. Without that algebraic anchor (−1), the proof has no foundation.
Gelfond and Schneider, independently in 1934, proved that αᵝ is transcendental when α is algebraic (not 0 or 1) and β is algebraic and irrational. This is how eᵖ was classified: rewrite eᵖ = (−1)^(−i), which is an algebraic base (−1) raised to an irrational algebraic power (−i, since i is algebraic). The theorem applies. eᵖ is transcendental.
Baker, in the 1960s and 70s, extended these results to linear combinations of logarithms of algebraic numbers. Nesterenko, in 1996, proved that π, eᵖ, and Γ(1/4) are algebraically independent — the strongest result in the neighborhood of πᵉ, but one that says nothing about πᵉ directly.
Every one of these theorems — spanning 150 years and multiple Fields Medals — requires at least one algebraic number in the expression. They are tools designed for a regime where transcendental quantities interact with algebraic ones.
πᵉ has no algebraic anchor. Both its base (π) and its exponent (e) are transcendental. No known rewrite produces an algebraic foothold. Every existing tool fails — not because it is weak, but because it was designed for a different regime. The tools are extraordinary. The blind spot is structural.
Edge intelligence breaks theory for the same structural reason.
Existing AI theory — PAC learning, VC dimension, statistical learning theory, the neural tangent kernel framework, scaling laws — assumes a regime where stochasticity averages out over large samples, errors are recoverable through retraining, optimization converges given enough steps, and uncertainty is tolerable because the cost of being wrong is bounded and symmetric.
Irreversibility breaks every one of those assumptions.
When you cannot retrain after a mistake because the mistake destroyed the system. When you cannot average over samples because you have one sample and it is happening now. When optimization cannot converge because the environment is non-stationary and your compute budget is a single forward pass. When uncertainty is not tolerable because the cost of being wrong is catastrophic and one-sided.
In this regime, existing theory does not degrade gracefully. It fails categorically. The assumptions are not approximately true — they are structurally false.
When failure is final, expectation is not enough.
VI. Prior Computational Context
We are not the first to notice that πᵉ is hard. The mathematical literature has flagged this constant for decades. What is missing is not awareness but action.
Nesterenko (1996) proved that π, eᵖ, and Γ(1/4) are algebraically independent. This is the strongest result in the immediate neighborhood of πᵉ, establishing that no polynomial relation exists among those three constants. But algebraic independence of {π, eᵖ} does not determine the algebraic status of πᵉ itself.
Bailey, Borwein, and Plouffe built the modern infrastructure of experimental mathematics. Their PSLQ algorithm is the standard tool for detecting integer relations among constants. Their surveys have tested related expressions — e + π and π/e have been searched up to degree 8 with coefficient bounds around 10⁹ — but we are not aware of a dedicated PSLQ study targeting πᵉ specifically.
Schanuel’s conjecture (1960s, still open) states that if α₁, ..., αₙ are complex numbers linearly independent over the rationals, then the transcendence degree of {α₁, ..., αₙ, e^α₁, ..., e^αₙ} over the rationals is at least n. If proven, it would immediately imply that πᵉ is transcendental — along with dozens of other open constants. Its power is precisely why it remains unproven.
The Ramanujan Machine project (Nature, 2021) demonstrated that automated conjecture generation can discover new mathematical identities for fundamental constants using algorithmic search and machine learning. Their methods have not been applied to πᵉ.
Computational searches for algebraic relations involving π and e have been conducted incidentally in broader surveys, but no dedicated, extended search targeting πᵉ to high degree and large coefficient bounds exists in the published literature as of early 2026.
The landscape is clear: πᵉ is universally cited as a canonical hard case, used as an example of what current theory cannot do, and then set aside. Everyone acknowledges the problem. Nobody has made it a project.
That is the gap we intend to fill — both computationally and architecturally.
VII. Why Schanuel’s Conjecture Matters — and Why It Won’t Save Us Soon
Schanuel’s conjecture, if proven, would instantly classify πᵉ as transcendental. It would also resolve the transcendence of e + π, eπ, eᵉ, ππ, and essentially every “simple” expression of fundamental constants that remains open. It would close the entire category of problems that πᵉ belongs to.
That is precisely why it remains unproven after more than sixty years.
Conjectures that powerful do not fall incrementally. The history of mathematics is unambiguous on this point. Fermat’s Last Theorem required Wiles to build an entirely new bridge between elliptic curves and modular forms — it did not yield to three centuries of incremental improvement on existing methods. The Poincaré conjecture required Perelman’s Ricci flow with surgery — a technique that did not exist when the conjecture was posed. The proof of the fundamental lemma in the Langlands program required Ngô Bảo Châu’s geometric approach — not a refinement of prior methods but a reconceptualization.
Schanuel’s conjecture will require something comparable. Not a better bound. Not a more sophisticated algebraic identity. A new way of thinking about the relationship between exponential functions and algebraic independence.
Nobody is close.
The best partial results — Baker’s theorem, Nesterenko’s work, various conditional results assuming weaker forms of Schanuel — chip away at the edges. They do not approach the center.
Waiting for Schanuel before acting on the problems it would resolve is like waiting for a unified field theory before building a bridge. The bridge needs to stand now. The theory can catch up.
Edge systems cannot wait. They must operate in the regime that existing theory cannot classify. They force new theory by existing — by generating empirical results, by demonstrating what works, by creating the data that theorists need to see before they know what to explain.
VIII. What the New Theory Must Look Like
The next theory of intelligence — the one that works at the edge, under irreversibility, with finite resources and physical constraints — will not be built on scale alone. It will be built on:
Admissibility instead of optimality. The goal is not the best answer. The goal is any answer within the set of safe, physically valid, constraint-satisfying responses. This is a fundamentally different mathematical object. Optimality requires a total ordering over outcomes and a search procedure. Admissibility requires a constraint set and a membership test. The second is often computationally cheaper, more robust, and more appropriate for safety-critical systems.
Worst-case reasoning instead of expectation. Expected value is the right objective when you play the game many times and can absorb variance. It is the wrong objective when you play the game once and the downside is catastrophic. Edge systems need minimax reasoning: what is the best I can guarantee under the worst conditions? This is older and more conservative than expected-value optimization. It is also more honest about what single-shot irreversible decisions actually require.
Structure-first design. The physics of the problem is not something to be learned from data. It is something to be built into the architecture. Conservation laws become hard constraints. Symmetries become equivariances. Kinematic limits become output bounds. The model does not get to discover that energy is conserved — it is forced to conserve energy by construction. This reduces the hypothesis space, improves generalization, and eliminates entire categories of physically impossible errors.
Physics embedded at the point of measurement. Not physics as a post-processing step. Not physics as a regularization term. Physics as the first layer of computation, running on the sensor itself, before data ever reaches a model. The sensor does not produce “data” — it produces physically constrained observations. The constraint is not downstream. It is upstream.
Explicit forbidden states. Traditional optimization has an objective to maximize. Edge systems also need a set of states that must never be reached, regardless of what the objective function says. A vehicle must never occupy the same space as a pedestrian. A medical device must never deliver a lethal dose. A power grid must never exceed thermal limits. These are not soft penalties. They are hard exclusions. The system must be provably incapable of reaching them, not statistically unlikely to.
Margins of safety as first-class objects. Engineering has understood margins of safety for centuries. A bridge rated for 10 tons is built to hold 20. That margin is not waste — it is the system’s buffer against model error, material variability, and unforeseen loads. AI systems at the edge need the same concept: quantified, tracked, and maintained margins between the system’s operating point and the boundary of failure. Not confidence intervals. Not uncertainty estimates. Actual structural margins, designed in and monitored continuously.
This is not anti-learning. It is learning constrained by reality. A system that learns within physical bounds will generalize better, fail less catastrophically, and earn trust faster than a system that learns without them.
IX. The πᵉ Principle
π represents magnitude — the full structural complexity of physical space, rotation, periodicity, geometry.
e represents optimal growth — the unique point where compounding efficiency is maximized.
Exponentiation is compounding over time.
When you put optimal efficiency in the base and full structure in the exponent, you get eᵖ = 23.141.
When you put magnitude in the base and efficiency in the exponent, you get πᵉ = 22.459.
The first wins. Always. Not by luck. By theorem.
That is the principle.
Not motivational. Not philosophical. Mathematical.
And it is the principle on which we build:
Efficient architectures (e) compounded over full physical structure (π) will outperform massive architectures (π) scaled by natural growth (e). At the edge, where resources are finite and physics is binding, this is not a preference. It is a necessity.
X. As Mathematicians, Physicists and Computer Scientists We Like Frontier of Unsolved Problems.
πᵉ is not interesting because it is mysterious. It is interesting because it is simple, precise, and still beyond classification.
That is how real frontiers announce themselves. Not with complexity, but with simplicity that existing tools cannot handle.
The simplest question — “is πᵉ irrational?” — has no answer, yet. Not because the question is vague. Not because the evidence is mixed. Not because nobody has looked. But because the structural prerequisites for an answer do not exist in current mathematics. The question is perfectly well-posed. The tools are perfectly well-developed. And they are perfectly insufficient.
The structural reason πᵉ resists classification is the same structural reason edge AI physics resists existing approaches. In both cases, the tools were built for a regime that does not apply. In both cases, progress requires something genuinely new — not refinements, not scale, not incremental improvement, but new conceptual foundations.
We do not claim to have an answer. We are committing to the question.
To build where existing tools fail. To operate where computation outruns explanation. To force new theory by necessity, not by declaration. To stand at the boundary that πᵉ marks and work from there.
Copyright © 2026 Gerard Rego
*This is personal research and documentation and is provided for research, ideas and evaluation purposes only.
All Rights Reserved. All data, organizations and other links are copyright of their respective owners. As part of this entire manuscript and all associated materials are protected by copyright, trademarks and patent applications pending. No part of this work may be reproduced, distributed, or used commercially without written permission. Commercial use prohibited without permission. No part of this work may be reproduced, distributed, or used to create derivative works without prior written permission of the author, except as permitted under applicable fair-use provisions for scholarly citation, review, or critique with proper attribution. This is personal research and documentation and is provided for research, ideas and evaluation purposes only